| Taesung Park Alexei A. Efros Richard Zhang Jun-Yan Zhu |
|
|
|
|
|
|
|
|
|
|
|

|
Paris to Burano Streets |

|
Russian Blue -> Grumpy Cats |
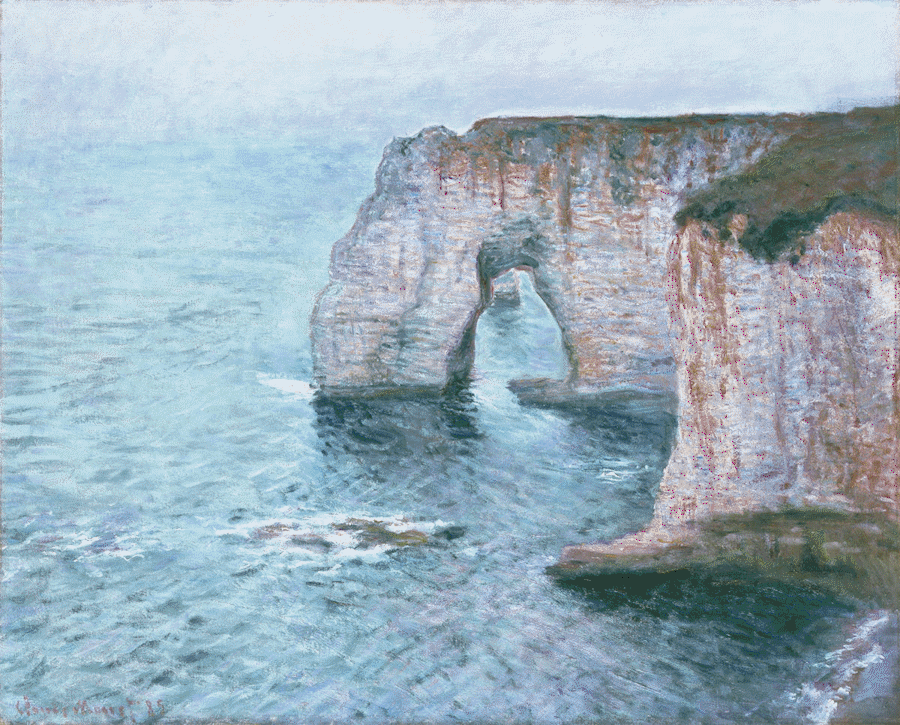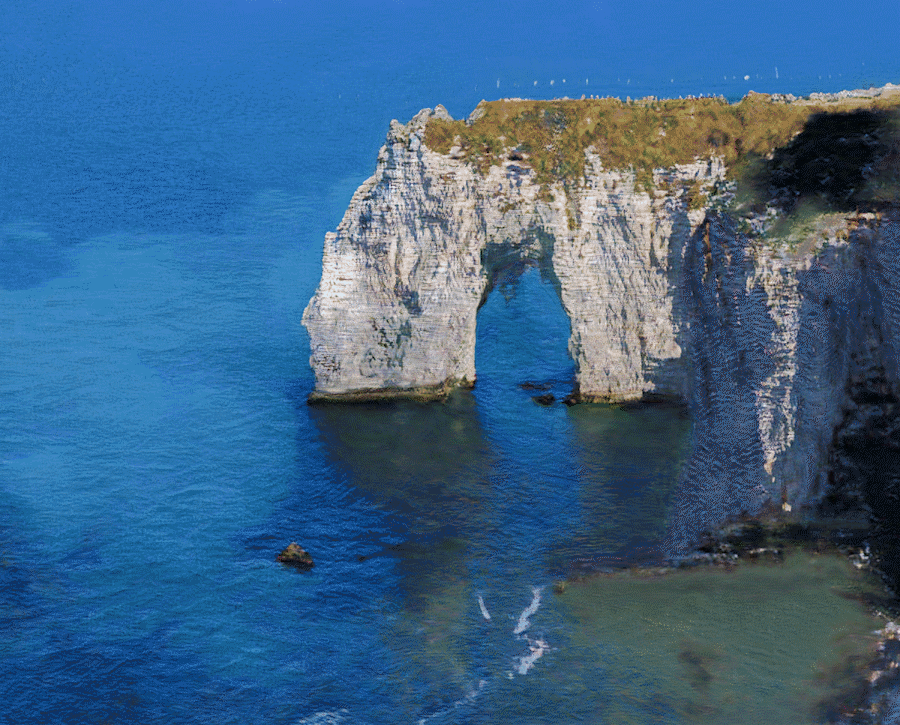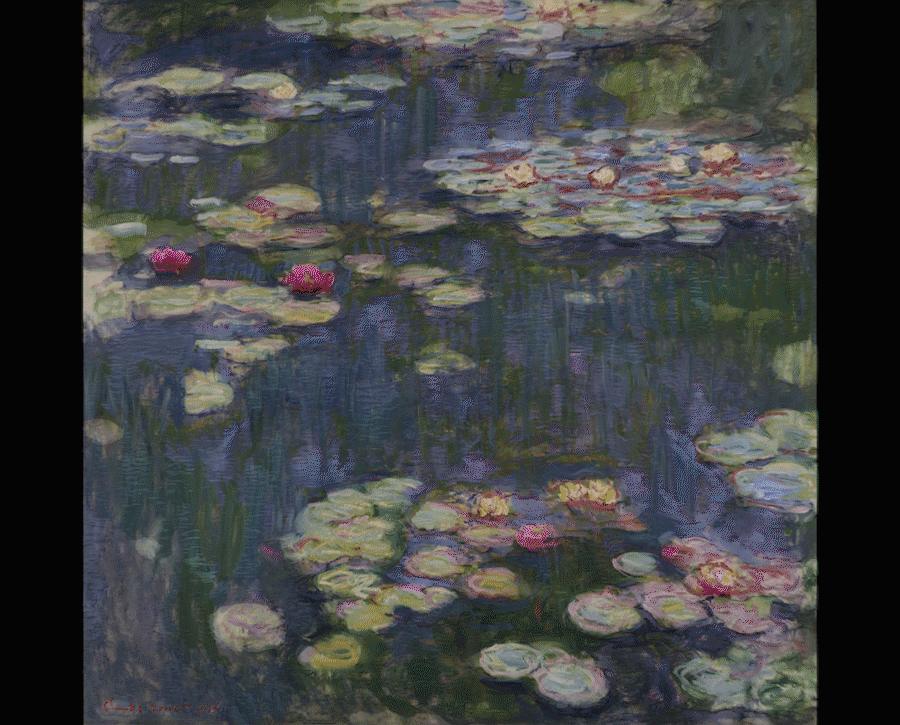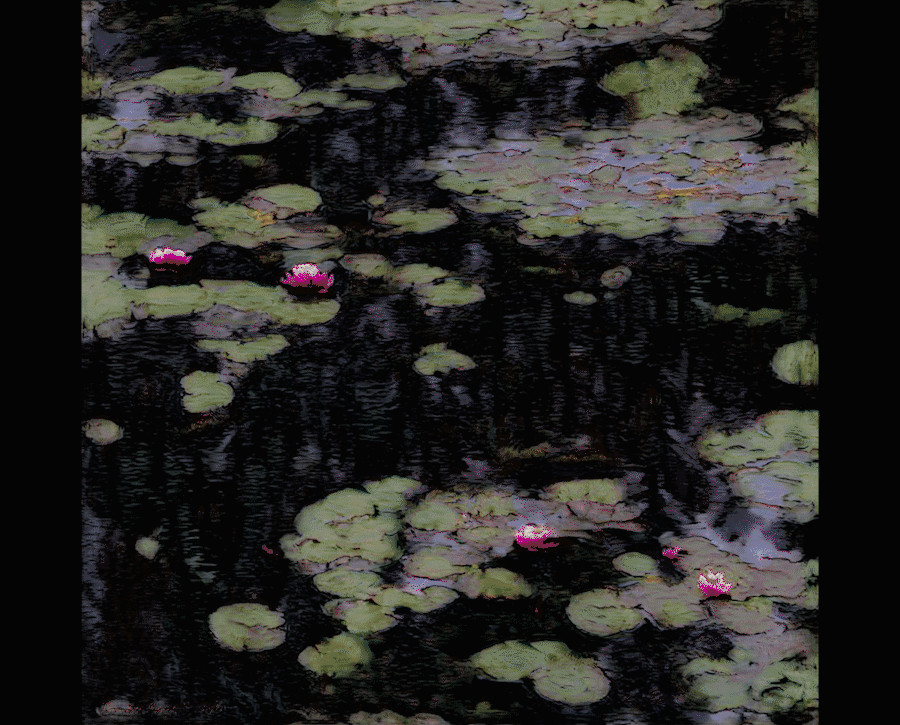
|
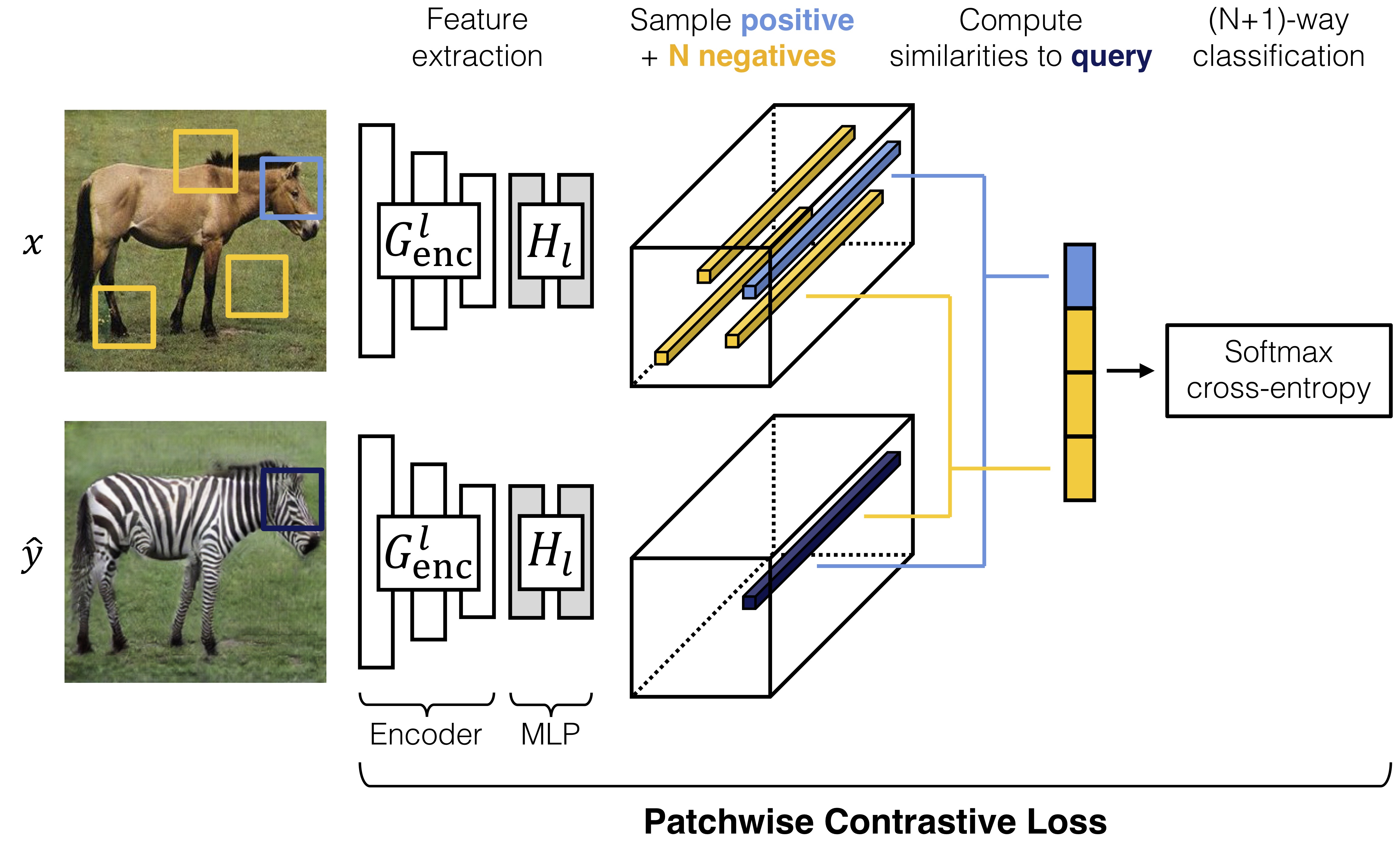
Single-Image Translation |
 |
 |
T. Park, A. A. Efros, R. Zhang, J.Y. Zhu. Contrastive Learning for Unpaired Image-to-Image Translation. In ECCV, 2020. |
Acknowledgements |